Contrastive Language-Image Pretraining¶
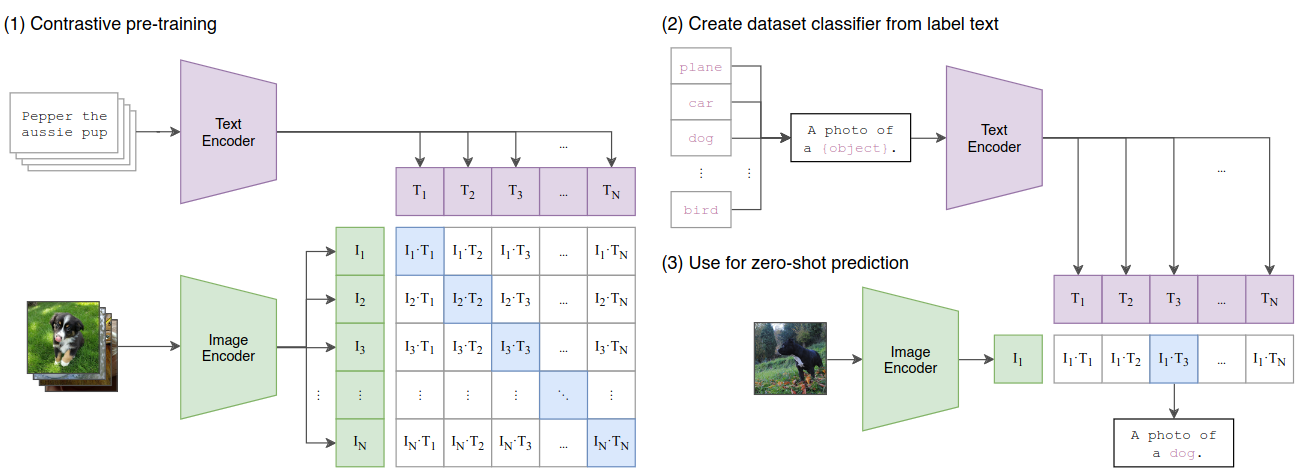
This paper presents an effective approach for pretraining vision models by leveraging natural language as a form of supervision. Typical computer vision systems are trained to predict images from a fixed set of predetermined categories. CLIP is instead trained on a large dataset of images that are captioned with natural language taken from the internet. Training involves matching captions with images in a batch which enables models to learn a wide variety of visual concepts in images and associate them with their names. This approach enables zero-shot transfer capabilities where the model can identify and categorize objects it was not explicitly trained to recognize.
Key Ideas¶
Natural language supervision is massively scalable in this context. A dataset of 400 million (image, text) pairs sourced from the internet enables pretraining on a much larger scale than traditional computer vision datasets with fixed object categories. Learning from raw descriptive text provides a richer and more flexible semantic context which expands beyond standard benchmark datasets.
An image encoder and a text encoder are trained simultaneously to predict correct pairings of images and text within a batch. The model maximizes the similarity between correct (image, text) pairs while minimizing the similarity between mismatched pairs. The objective function is formulated as a symmetric cross entropy loss over the cosine similarity where $I$ and $T$ are the image and text embeddings and $\tau$ is a tunable temperature parameter.
\begin{gather} \mathcal{L}_{i,j} = - log \frac{exp(sim(I_i, T_j) / \tau)}{\sum_{i \neq k} exp(sim(I_i, T_k) / \tau)} \\ sim = \frac{A \cdot B}{||A|| ||B||} \end{gather}
- The text encoder can be used to generate labels for new images which allows for application to new classification tasks without needing additional specific training.
Results¶
Performance was tested across more than 30 existing computer vision datasets covering tasks from optical character recognition to fine-grained object classification with a variety of model architectures. CLIP matched or exceeded the zero-shot performance of previous models across most evaluated tasks where it demonstrated the capability to generalize from natural language supervision to a wide array of visual tasks without additional task-specific training. Notably, it achieved competitive performance to the original ResNet-50 on ImageNet in a zero-shot setting. CLIP has been a foundational piece of research for modern generative and multimodal learning tasks by learning a rich and semantic understanding of images with textual descriptions.