2021
MLP Mixer
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy
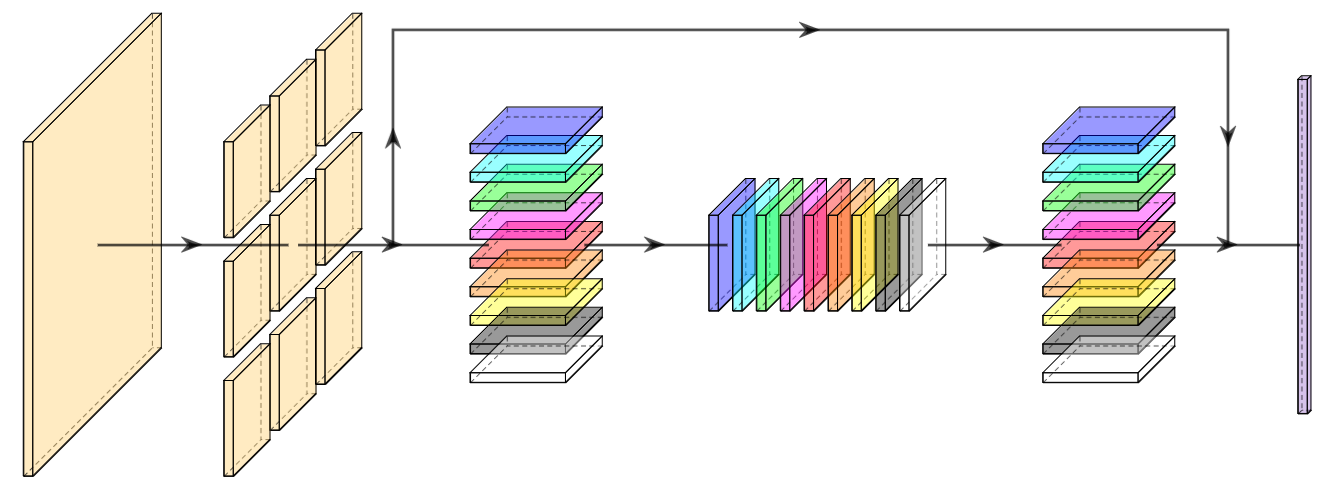
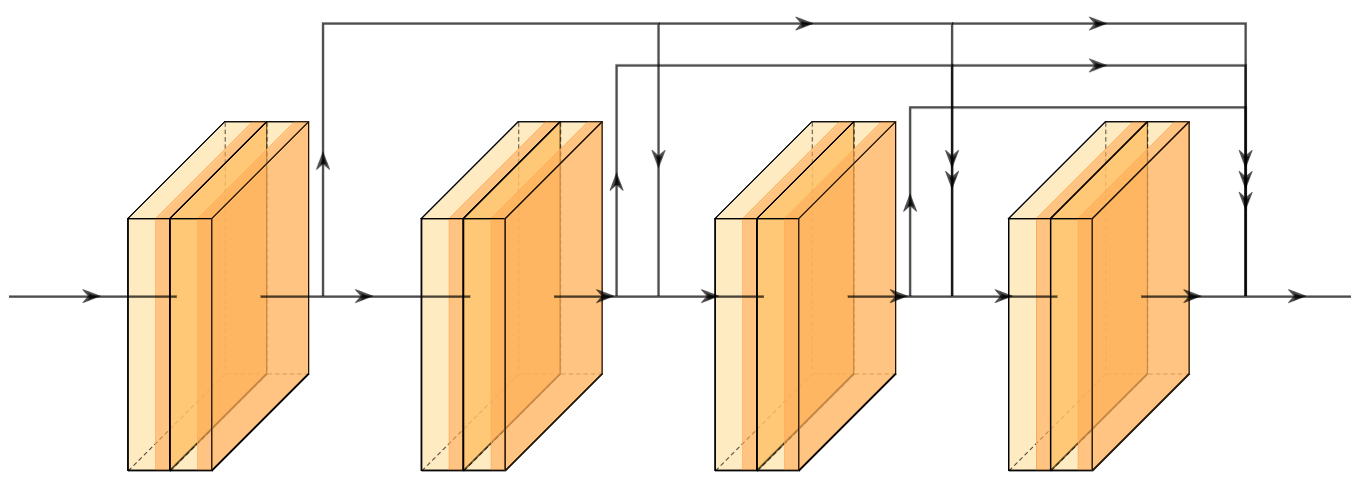
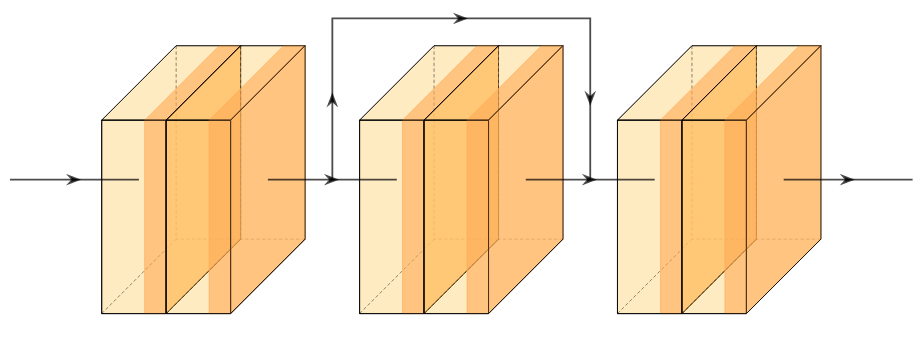
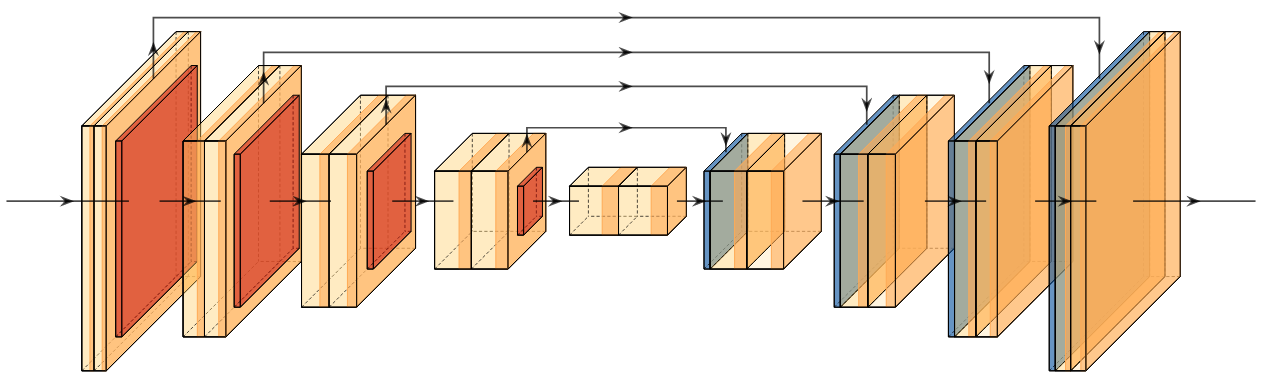
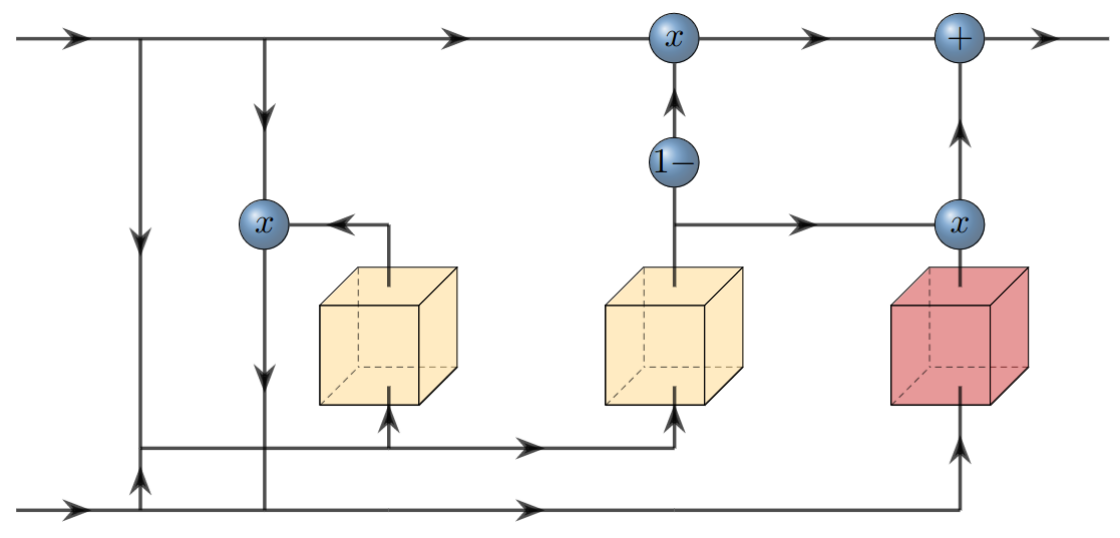
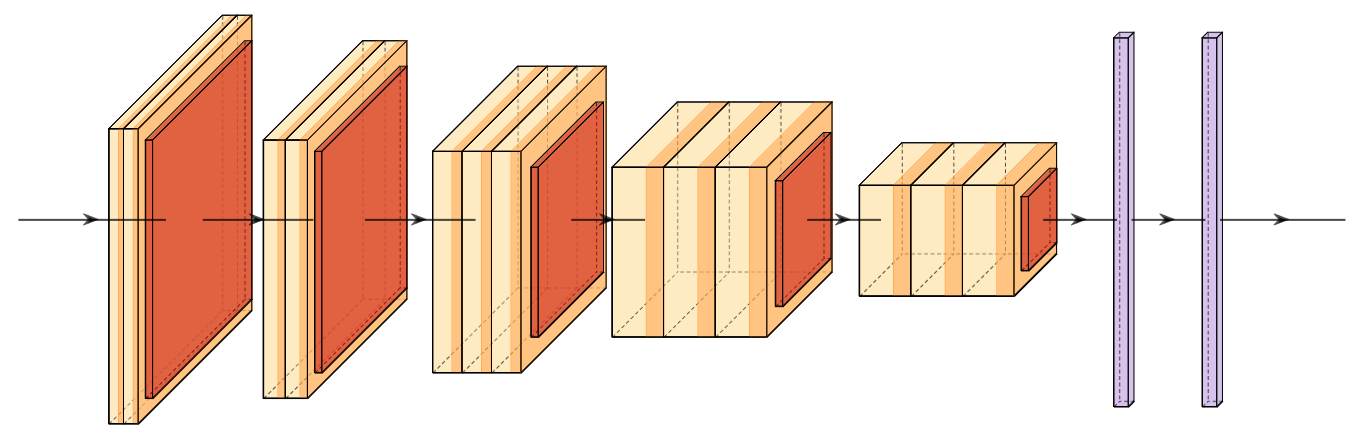
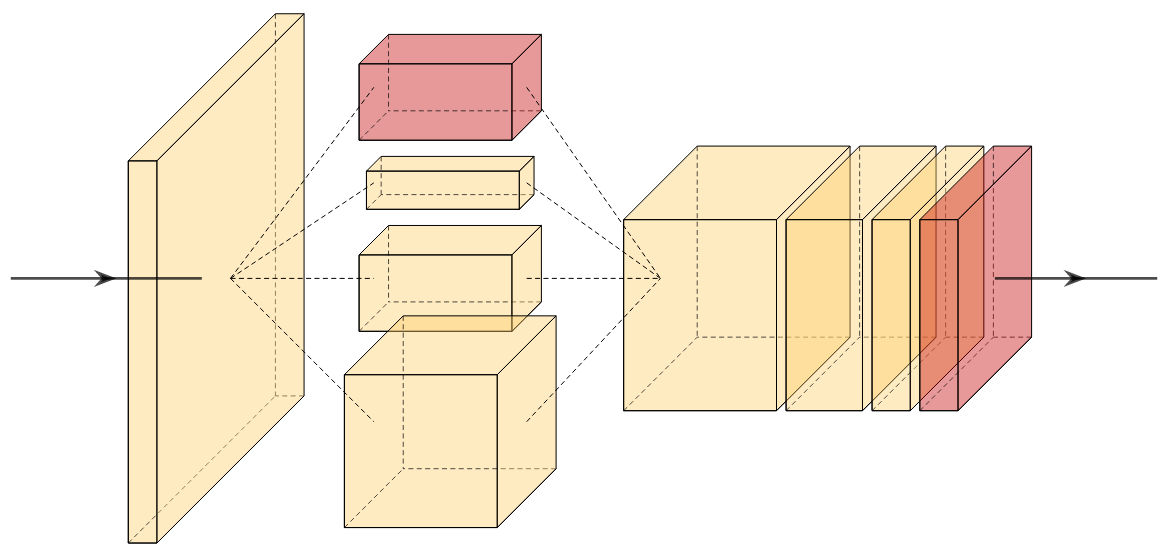
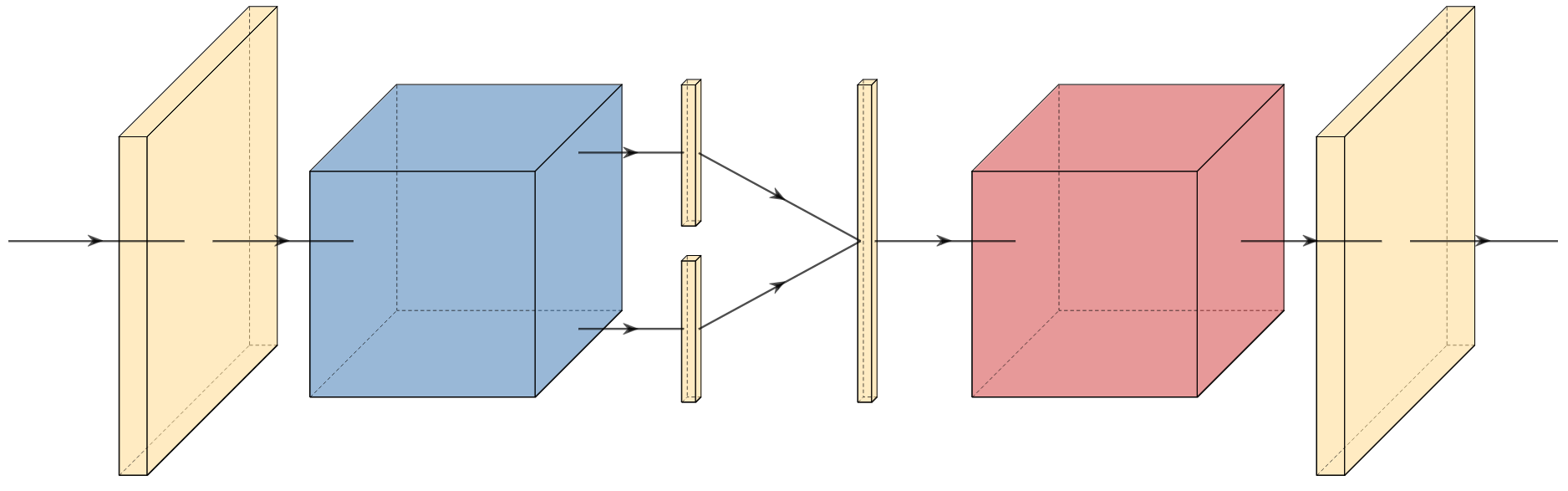
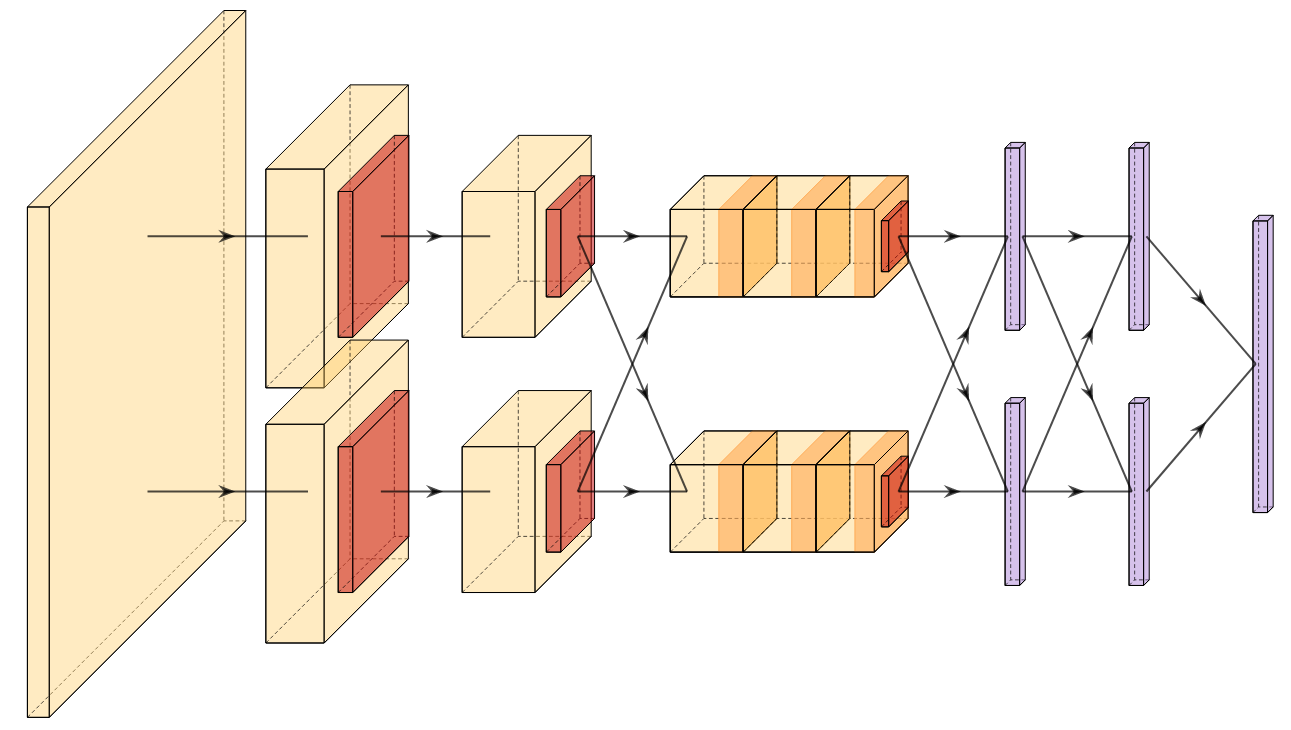
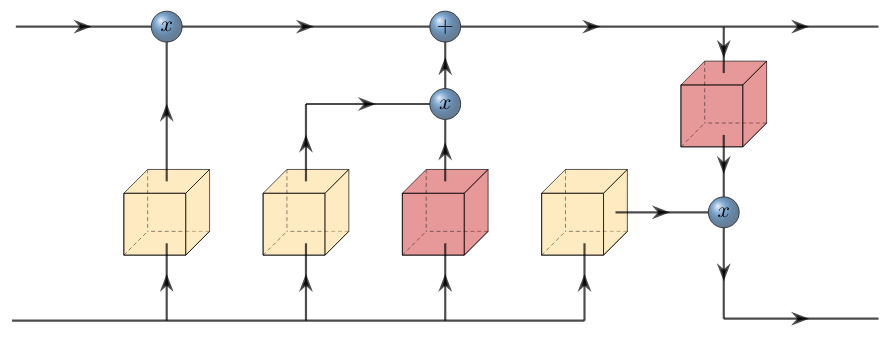
A new take on vision architectures that eschew convolution and attention for only fully connected layers. MLP mixer applies spatial embeddings to the input image and then applies permutation-invariant operations through channel and token mixing layers.